AIの知識ギャップを埋めるMCPサーバー開発者ガイド
これまでに、AIアシスタントに十分に理解していないフレームワークのコード生成を依頼したことはありますか?見た目は正しそうでも、構文が少し間違っていたり、非推奨のパターンを使っていたりすることがあるかもしれません。AIは懸命に動いていますが、あなたを本当に助けるために必要な具体的なコンテキストが不足しているのです。
モデル・コンテキスト・プロトコル(MCP)は、AIアシスタントに組み込みでは持っていないドメイン特有の知識や機能へのアクセスを提供することで、この知識ギャップを埋めるために設計されました。
MCPとは何ですか?
MCPは、AIクライアントがリモートサーバとどのように通信するかを定義するオープンスタンダードです。Claude、Cursor、VS Codeのようなクライアントが、外部システムのツール、リソース、機能にアクセスするための標準化されたプロトコルを提供します。
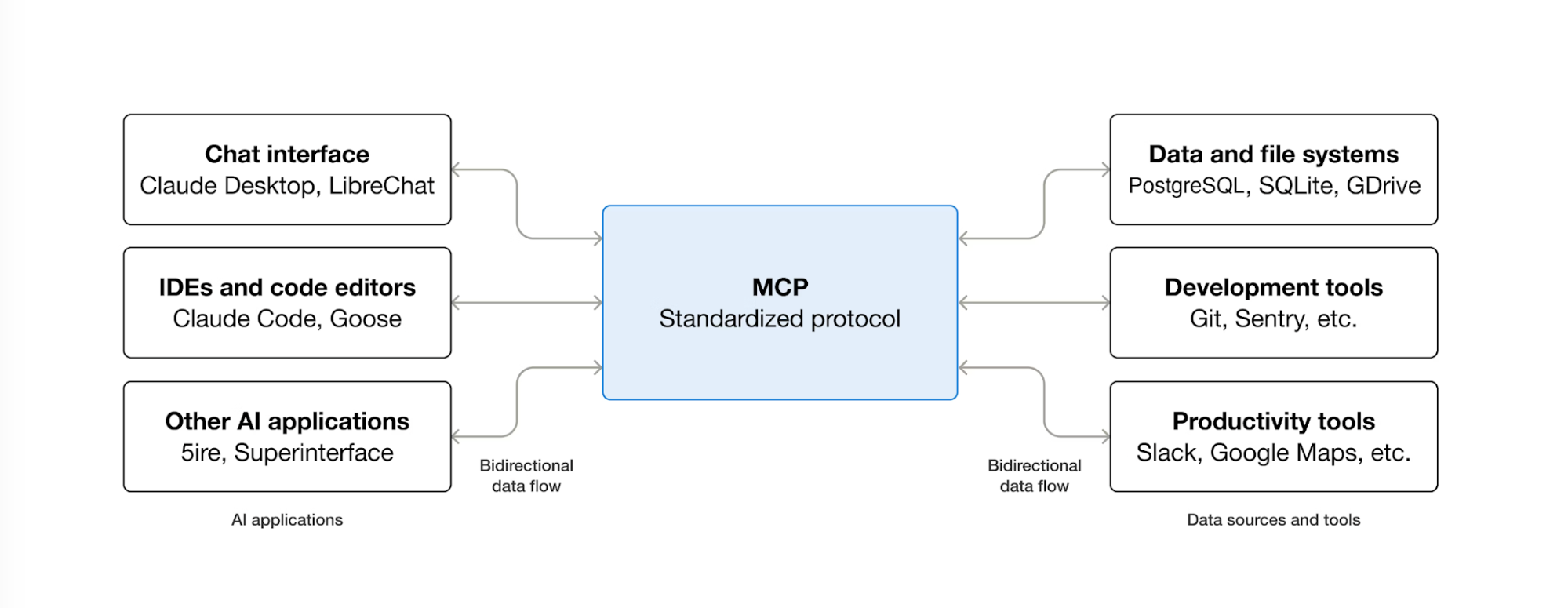
現在、MCPサーバーはAIクライアントに対していくつかの種類の機能を公開できます。
- リソース:ドキュメント、設定ファイル、APIレスポンスなど、クライアントが読み取ることのできるデータ
- ツール:AIが呼び出してアクションを実行したり、データを取得したり、コンテンツを検証したりできる関数
- プロンプト:ユーザーが特定のタスクを達成するのを支援する、あらかじめ構造化されたメッセージテンプレートや指示
このプロトコルは進化を続けており、2025年には複数の仕様バージョンが公開され、将来の機能に向けたドラフト仕様も存在します。上記の3つの中核プリミティブが基盤を形成していますが、エコシステムは今後さらに拡大していくことが予想されます。
なぜ自分のMCPサーバーを構築するのか?
MCPは、自分の特定のドメインに合わせてサーバーを構築したときに最も効果を発揮します。エコシステムには多くの一般的な統合やデータソース向けのサーバーが含まれていますが、あなたやあなたの組織には独自の要件があり、カスタム実装が必要な場合があります。
次のようなシナリオを考えてみてください:
- チームがAIに会社固有のデータや内部ツールへのアクセスを必要とする場合
- 複数のシステム(CI/CD、課題管理、デプロイ)にまたがるワークフローを自動化したい場合
- AIアシスタントが持っていないドメイン専門知識や特殊な知識を持っている場合
- 組織内のAPIやサービスをAIのワークフローに統合する必要がある場合
これらのそれぞれの場合に、AIアシスタントが正確に知るべきことを教えるMCPサーバーを構築することができます。
実際の例:MDCシンタックスヘルパー
実際の例を見てみましょう:Kong開発者ポータル向けに構築しているMCPサーバーです。
Kongの開発者ポータルでは、顧客がMDCシンタックスを使用してMarkdownを強化し、Markdown内でスロットやプロパティを持つVueコンポーネントを統合できるカスタムページを作成できます。ユーザーは階層的なページ構造を構築し、リッチなコンポーネント、カスタムメタデータ、スタイル付きコンテンツブロックを使用して、完全にブランディングされた開発者向け体験を作り上げることができます。
問題は、AIアシスタントはMDCシンタックスを本質的に理解しておらず、利用可能なコンポーネントを把握していないことです。ユーザーがAIアシスタントやMCPクライアントにポータルコンテンツ作成の支援を求めると、クライアントは無効なシンタックスを生成したり、存在しないコンポーネントを提案したりする可能性があります。
これは重要です。なぜなら、MDCは単にテキストをフォーマットするためのものではないからです。顧客はMDCを使って、全幅のヒーローセクション、レスポンシブな特徴グリッド、スタイライズされたカードなどを備えたプロフェッショナルなブランドページを作成するために利用しています。
こちらは、MDCでのシンプルなヒーローセクションの例です:
::page-hero
---
full-width: true
title-color: "#ffffff"
description-color: "#e0e7ff"
background-color: "#29417a"
border-radius: "0"
padding: "80px 40px"
text-align: "center"
---
#title
Ship Faster with Our Payment API
#description
Process payments, manage subscriptions, and handle refunds with a single integration. Get started in minutes with our comprehensive SDKs.
#actions
:::button
---
appearance: "primary"
size: "large"
to: "#docs"
background-color: "#3b82f6"
---
View Documentation
:::
::そして、同じヒーローセクションがポータル上で表示される様子は以下の通りです:

MDCシンタックスや利用可能なコンポーネントを理解していなければ、AIアシスタントはユーザーがこれらのコンテンツセクションやページ全体を効果的に作成する手助けができません。
私たちが構築しているMCPサーバーは、この知識ギャップを埋めるために設計されており、AIクライアントにMDCシンタックスを教え、コンポーネントの例やメタデータを提供し、オフライン参照用のリソースをまとめ、ユーザーに届く前にエラーを検出するためのシンタックス検証ツールを公開します。
AIアシスタントにMDCを教えるツール
- 完全なMDCドキュメントを返すシンタックスガイド
- ポータルのAPIから利用可能なすべてのコンポーネントを取得するコンポーネント一覧
- プロパティ、スロット、型情報を取得するコンポーネントメタデータ取得機能
- 各コンポーネントの実際の使用パターンを示す使用例
- 生成されたMDCを検証し、行番号や詳細なメッセージでエラーを報告するシンタックスバリデーター
オフライン参照用の静的リソース
- オフラインアクセス用にまとめられたMarkdownドキュメント
- 一貫したスタイリングのためのデザイントークン参照
すべてをまとめると:AIクライアントのワークフロー
ユーザーがポータルコンテンツ作成の支援を求めると、AIクライアントは次の自然なワークフローに従います:
- シンタックスガイドを呼び出して、MDCのルールと構造を理解する
- 利用可能なコンポーネントを確認し、そのメタデータ(プロパティ、スロット、インターフェース)を取得する
- 実際の使用例を確認して、パターンを把握する
- コンテンツを生成し、シンタックスバリデーターでエラーをチェックする
最終的に得られるのは、実際のポータルコンポーネントを使用し、正しいシンタックスとブランドスタイルを備えた検証済みのMDCコンテンツで、すぐに公開可能です。
このパターンは、カスタムシンタックス、コンポーネントライブラリ、またはAIが理解する必要のあるAPIがある場合にも適用できます。MCPサーバーは、AIアシスタントがあなたの特定のツールやフォーマットで作業できるよう支援します。
MCPサーバーの構築
ゼロからMCPサーバーを構築してみましょう。TypeScriptを使用し、リモートMCPサーバーに適したCloudflare WorkersのAgents SDKにデプロイします。
プロジェクトのセットアップ
まず、新しいプロジェクトを作成し、依存関係をインストールします:
mkdir my-mcp-server && cd my-mcp-server && pnpm init必要な依存関係をインストールします:
pnpm add @modelcontextprotocol/sdk agents zod開発用依存関係をインストールします:
pnpm add -D typescript wrangler @types/node各パッケージの役割は以下の通りです:
- @modelcontextprotocol/sdk:MCPサーバー構築用の公式SDK
- agents:Cloudflare Workers上でMCPサーバーを構築するためのAgents SDK
- zod:ツールの入力パラメータのスキーマ検証
- wrangler:Cloudflareのローカル開発およびデプロイ用CLI
TypeScriptの設定
tsconfig.json を作成します:
{
"compilerOptions": {
/* Language and Environment */
"target": "ES2021",
"lib": ["ES2022"],
/* Modules */
"module": "ES2022",
"moduleResolution": "bundler",
"allowImportingTsExtensions": true,
"verbatimModuleSyntax": true,
"resolveJsonModule": true,
"types": ["node", "./worker-configuration.d.ts"],
/* Emit */
"noEmit": true,
/* Interop Constraints */
"isolatedModules": true,
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
/* Type Checking */
"strict": true,
"noUncheckedIndexedAccess": true,
"noImplicitReturns": true,
"noFallthroughCasesInSwitch": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
"allowUnreachableCode": false,
/* Completeness */
"skipLibCheck": true
},
"include": ["src/**/*.ts"]
}Wranglerの設定
Cloudflare Workerを設定するために、wrangler.toml ファイルを作成します:
main = "./src/index.ts"
name = "my-mcp-server"
compatibility_date = "2026-01-01"
compatibility_flags = ["nodejs_compat"]
# Bundle markdown files as text assets
rules = [
{ type = "Text", globs = ["**/*.md"], fallthrough = true }
]
# Durable Objects for persistent state
[[durable_objects.bindings]]
name = "MCP_OBJECT"
class_name = "MyMcpServer"
[[migrations]]
tag = "v1"
new_sqlite_classes = ["MyMcpServer"]いくつか注意点があります:
- 上記の rules セクションは、.md ファイルをテキストとしてバンドルするようWranglerに指示しており、ドキュメントをサーバーに直接含めたい場合に便利です
- Durable Objects の設定により、各MCPサーバーインスタンスが独自の永続的な状態を持つことができます
- 開発用と本番用で分離されたデプロイを行いたい場合は、別々の環境(例:[env.dev] と [env.prod])を定義できます
MCPサーバー
では、サーバーを作成しましょう。src/index.ts を作成し、ステップごとに構築していきます。
インポートと型定義
まず、インポートとサーバー用の状態インターフェースを定義します:
// src/index.ts
import { Agent, getAgentByName } from 'agents'
import { createMcpHandler } from 'agents/mcp'
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'
import { z } from 'zod'
// Define your server state (can be empty or hold session data)
interface State {}Agent クラスはステートフルなWorkerの基盤を提供します。createMcpHandler 関数は、MCPプロトコルに対応するHTTPハンドラーを生成します。リクエスト間でデータを保持する必要がある場合は、State インターフェースにプロパティを追加できます。
Agentクラス
次に、Agent を継承したサーバークラスを作成します:
// src/index.ts
export class MyMcpServer extends Agent<Env, State> {
server = new McpServer({
name: 'My MCP Server',
description: 'Helps AI clients generate and validate MDC content for the portal. **START HERE: Read the syntax guide resource first** to learn MDC rules before using other tools. Typical workflow: (1) Read mdc://docs/components resource, (2) list_components, (3) get_component_metadata, (4) get_component_examples (5) validate_mdc_syntax.',
version: '1.0.0',
})
}McpServer インスタンスは、サーバーのメタデータを保持し、ツールやリソースの登録を管理します。クライアントは接続時にこの名前と説明を確認します。
重要:description フィールドには、AIクライアントがサーバーを効果的に使用する方法を示す内容を記載する必要があります。最初に呼び出すツール、前提条件、典型的なワークフローの順序などを含めましょう。AIクライアントはこれを利用して意図された使用パターンを理解するため、最も重要な情報を冒頭に優先して記載してください。
ツールの登録
onStart() ライフサイクルメソッドは、すべてのツールやリソースを登録する場所です。
以下は、APIからコンポーネントメタデータを取得するツールの例です。
まず、入力と出力のスキーマを含むツールのメタデータを定義します:
// src/index.ts
async onStart() {
this.server.registerTool(
'get_component_metadata',
{
title: 'Get Component Metadata',
description: 'Retrieves metadata for a specific component including props and slots.',
inputSchema: {
componentName: z.string().describe('The component name in kebab-case'),
},
outputSchema: z.looseObject({}).describe(
'Component metadata including available props, types, slots, and documentation'
),
},
// Handler implementation below...
)
}
次に、メタデータを取得して返すハンドラーを実装します:
// src/index.ts
async onStart() {
this.server.registerTool(
'get_component_metadata',
{ /* ...metadata from above */ },
async (params: { componentName: string }) => {
try {
const requestUrl = `https://example.com/api/components/${params.componentName}`
const response = await fetch(requestUrl)
if (!response.ok) {
return {
content: [{
type: 'text',
text: `Component "${params.componentName}" not found`
}],
isError: true,
}
}
const result = await response.json()
return {
content: [{
type: 'text',
text: `\`\`\`json\n${JSON.stringify(result, null, 2)}\n\`\`\``,
}],
structuredContent: result as Record<string, unknown>,
}
} catch (error) {
return {
content: [{ type: 'text', text: `Error: ${error.message}` }],
isError: true,
}
}
},
)
}
ツールは、名前、入力/出力スキーマを含むメタデータ、非同期ハンドラーの3つの要素で構成されます。outputSchema は structuredContent の構造を定義しており、AIクライアントは人間が読めるコンテンツと一緒にプログラム的に解析できます。
この例は、外部データを取得するツールの基本パターンを示しています:入力を検証し、APIリクエストを行い、isError: true でエラーを処理し、人間が読めるテキストと構造化データの両方を返します。
ツールの説明のベストプラクティス:説明は簡潔に(1〜2文)し、最も重要な情報を先に記載します。ツールを使用するタイミングや理由、前提条件、ワークフロー内での位置を明示すると、AIクライアントが意図された使用パターンを理解しやすくなります。
リソースの登録
リソースは、クライアントが必要に応じて読み取れるデータを公開します。onStart() メソッドを拡張して、リソースも登録します:
// src/index.ts
async onStart() {
// ... tool registration from above
this.server.registerResource(
'component_docs',
'mdc://docs/components',
{
title: 'Component Documentation',
description: 'Complete reference for all available MDC components including layouts and content blocks. Use after reading syntax guide to see component capabilities.',
mimeType: 'text/markdown',
},
async (uri: any) => {
const content = `# MDC Components
## Layout Components
- **page-hero**: Full-width hero sections with title, description, and actions
- **page-section**: Content sections with optional backgrounds
- **multi-column**: Responsive grid layouts
## Content Components
- **card**: Styled content cards with optional images
- **accordion**: Collapsible content sections
- **tabs**: Tabbed content panels`
return {
contents: [
{
uri: uri.href,
mimeType: 'text/markdown',
text: content,
},
],
}
},
)
}
リソースはカスタムURIスキーム(例:mdc://docs/components)で識別されます。ツールがAIによって必要に応じて呼び出されるのに対し、リソースは通常、クライアントが参照資料を必要とする際に一度読み取られます。リソースの説明も同様に簡潔にし、使用するタイミング、前提条件、ワークフロー上の文脈を明示してください。
MCPリクエストの処理
MyMcpServer クラスに、受信したMCPプロトコルリクエストを処理するメソッドを追加します:
// src/index.ts
export class MyMcpServer extends Agent<Env, State> {
// ... server property and onStart() from above
async onMcpRequest(request: Request): Promise<Response> {
return createMcpHandler(this.server)(request, this.env, {} as ExecutionContext)
}
}
createMcpHandler 関数は、McpServer インスタンスを受け取り、MCPプロトコルを実装したHTTPハンドラーを返します。これにより、クライアントとサーバー間の双方向メッセージングが処理されます。
フェッチハンドラー
最後に、リクエストをMCPサーバーにルーティングするデフォルトハンドラーをエクスポートします:
// src/index.ts
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
const url = new URL(request.url)
if (url.pathname === '/mcp') {
// Get session ID from header or generate a new one
const sessionId = request.headers.get('mcp-session-id') ?? crypto.randomUUID()
// Retrieve the agent instance for this session
const agent = await getAgentByName<Env, MyMcpServer>(env.MCP_OBJECT, sessionId)
return agent.onMcpRequest(request)
}
return new Response('Not found', { status: 404 })
},
}
getAgentByName 関数は、各セッションに対応するDurable Objectインスタンスを取得(または作成)します。これにより、接続された各クライアントが独立した状態を持つことができます。セッションIDは mcp-session-id ヘッダーに含まれており、新しい接続の場合は自分で生成することも可能です。
内部で何が起きているのか
アーキテクチャをまとめると:
- Agentクラス:Cloudflare Agents SDKのAgentを拡張し、Durable Objectの状態やライフサイクルフックにアクセス可能
- McpServerインスタンス:サーバーのメタデータと登録されたツール/リソースを保持
- onStart() ライフサイクル:Agent初期化時に呼び出され、機能登録に最適
- createMcpHandler():MCPプロトコルを実装したHTTPハンドラーを生成
- getAgentByName():セッションIDでAgentインスタンスを取得し、クライアントごとの状態を管理
永続的なセッション状態の追加
上記の基本例はステートレスサーバーでは十分ですが、実際のMCPサーバーではリクエスト間でセッション状態を保持する必要があります。その場合、Durable Objectストレージを備えた WorkerTransport を追加できます。
まず、インポートを更新します:
// src/index.ts
import { Agent, getAgentByName } from 'agents'
import { createMcpHandler, WorkerTransport } from 'agents/mcp'
import type { TransportState } from 'agents/mcp'
次に、Agent クラスにトランスポートのインスタンスを追加します:
// src/index.ts
const STATE_KEY = 'mcp-transport-state'
export class MyMcpServer extends Agent<Env, State> {
server = new McpServer({
name: 'My MCP Server',
description: 'A custom MCP server that provides domain-specific knowledge.',
version: '1.0.0',
})
// Worker transport for Streamable HTTP with persistent state
transport = new WorkerTransport({
sessionIdGenerator: () => this.name,
storage: {
get: async () => {
return await this.ctx.storage.get<TransportState>(STATE_KEY)
},
set: async (state: TransportState) => {
await this.ctx.storage.put(STATE_KEY, state)
},
},
})
}
最後に、onMcpRequest() メソッドを更新して、createMcpHandler にトランスポートを渡します:
// src/index.ts
export class MyMcpServer extends Agent<Env, State> {
// ... server and transport properties from above
async onMcpRequest(request: Request): Promise<Response> {
return createMcpHandler(this.server, {
transport: this.transport,
})(request, this.env, {} as ExecutionContext)
}
}
WorkerTransport は、Durable Objectのストレージを使用してリクエスト間でセッション状態を保持します。これにより、ユーザー入力を求める「エリシテーション」や、クライアントからAI補完を取得する「サンプリング」などの高度なMCP機能が可能になります。ほとんどのサーバーでは基本のステートレス方式で十分ですが、WorkerTransport を追加することで、MCPプロトコルのすべての機能を活用できます。
より高度なツールの追加
ツールは、構文解析や検証のような複雑な操作も実行できます。以下は、MDCのバリデーターの例で、構文エラーのチェック、コンポーネント構造の検証、ネストされたコンポーネントが正しく形成されているかを確認します。
まず、検証結果のスキーマを含むツールのメタデータを定義します:
// src/index.ts
async onStart() {
this.server.registerTool(
'validate_mdc_syntax',
{
title: 'Validate MDC Syntax',
description: 'Validates MDC content and reports syntax errors with line numbers.',
inputSchema: {
content: z.string().describe('The MDC content to validate'),
},
outputSchema: z.object({
valid: z.boolean().describe('Whether the MDC content is valid'),
error_count: z.number().describe('Total number of errors found'),
errors: z.array(z.object({
line: z.number().describe('Line number where the error occurred'),
message: z.string().describe('Description of the error'),
})).describe('List of validation errors'),
}),
},
// Handler implementation below...
)
}
次に、ネストされたコンポーネントを追跡するためのスタックを使って、バリデーションロジックを実装します:
// src/index.ts
async onStart() {
this.server.registerTool(
'validate_mdc_syntax',
{ /* ...metadata from above */ },
async (params: { content: string }) => {
const errors: Array<{ line: number; message: string }> = []
const lines = params.content.split('\n')
const stack: Array<{ name: string; colons: number; line: number }> = []
lines.forEach((line, i) => {
const openMatch = line.match(/^(:{2,})([\w-]+)/)
const closeMatch = line.match(/^(:{2,})\s*$/)
if (closeMatch && !openMatch) {
if (stack.length === 0) {
errors.push({ line: i + 1, message: 'Closing tag without opening' })
} else {
if (closeMatch[1].length !== stack[stack.length - 1].colons) {
errors.push({ line: i + 1, message: `Mismatched colons for "${stack[stack.length - 1].name}"` })
}
stack.pop()
}
} else if (openMatch) {
stack.push({ name: openMatch[2], colons: openMatch[1].length, line: i + 1 })
}
})
stack.forEach(c => errors.push({ line: c.line, message: `"${c.name}" not closed` }))
const result = { valid: errors.length === 0, error_count: errors.length, errors }
return {
content: [{
type: 'text',
text: result.valid ? '✓ Valid' : `Errors:\n${errors.map(e => `Line ${e.line}: ${e.message}`).join('\n')}`,
}],
structuredContent: result,
isError: errors.length > 0,
}
},
)
}
このバリデーターは、より高度なツールロジックの例を示しています:
- ネストされたコンポーネントを追跡するためにスタックを使用し、正しい入れ子構造を保証
- 開始タグと終了タグのコロン数が一致していることを検証
- 特定の行番号付きで構造化されたエラー情報を返す
- 人間が読める要約と、structuredContent を通じたプログラムによるアクセスの両方を提供
ツールとリソースの整理
MCPサーバーが大きくなるにつれて、ツールとリソースを別ファイルに整理したくなります。よく使われるパターンとして、Registrable インターフェースを作成する方法があります:
// src/types/registrable.ts
import type { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'
export interface Registrable {
register(): void
}
その後、各ツールやリソースをそれぞれ独立したクラスとして定義します:
// src/tools/validate-component.ts
import type { Registrable } from '../types/registrable'
import type { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'
import { z } from 'zod'
export class ValidateComponentTool implements Registrable {
constructor(private server: McpServer) {}
register() {
this.server.registerTool(
'validate_component',
{
title: 'Validate Component',
description: 'Validates component usage.',
inputSchema: {
componentName: z.string().describe('The component name'),
},
},
async (params: { componentName: string }) => {
// Validation logic here
return {
content: [{ type: 'text', text: 'Valid!' }],
}
},
)
}
}
そして、メインファイルでは次のようにします:
// src/index.ts
async onStart() {
new ValidateComponentTool(this.server).register()
new ListComponentsTool(this.server).register()
// ... more tools
}
これによりコードが整理され、機能の追加や削除が簡単になります。
実際に動かしてみる
MCPサーバーがClaudeやCursorのようなクライアントに接続されると、次のような流れになります。ユーザーは例えば次のように尋ねます:
"Create a getting started guide with a branded page hero, followed by sections showcasing installation steps, platform features, and a 'Hello World' example."
AIクライアントは、自動的に component_docs リソースを読み込み、page-hero や card コンポーネントについて学習します。その後、MDCコンテンツを生成し、validate_mdc_syntax ツールを呼び出して構文が正しいことを確認した上でユーザーに提示します。ユーザーは、どのツールが呼ばれたかや、MCPプロトコルが裏でどのように動いているかを知る必要はありません。
ローカル開発とデプロイ
ローカルでの実行
package.json にスクリプトを追加します:
{
"scripts": {
"dev": "wrangler dev --port 8787",
"deploy": "wrangler deploy",
"types": "wrangler types"
}
}
ローカル開発サーバーを起動します:
pnpm dev
MCPサーバーが http://localhost:8787 で起動しました。次の方法でテストできます:
- MCPクライアントを http://localhost:8787/mcp に接続する
- MCP Inspector を使ってサーバーの機能を確認する
- 直接HTTPリクエストを送信して特定のエンドポイントをテストする
MCP InspectorのUIですぐに動作確認を始めるには、次のコマンドを実行します:
pnpm dlx @modelcontextprotocol/inspector
サーバーが起動し、UIは http://localhost:6274 でアクセス可能になります。

Cloudflareへのデプロイ
デプロイの準備ができたら:
pnpm deploy
Wrangler は Worker をデプロイし、https://my-mcp-server.your-account.workers.dev のようなURLを提供します。その後、このURLにMCPクライアントを接続するか、Workerをカスタムホスト名や既存ドメインの特定パスにマッピングすることも可能です。
MCPクライアントの接続
リモートMCPサーバーは、通信にStreamable HTTPを使用します。このトランスポートは、クライアントとサーバー間の双方向メッセージングに単一の /mcp エンドポイントを使用します。
ほとんどのMCPクライアントは、サーバーのURLに /mcp パスを付けて接続するよう設定できます:
https://my-mcp-server-prod.workers.dev/mcp
具体的な設定手順はクライアントごとに異なるため、詳細なセットアップは利用するMCPクライアントのドキュメントを参照してください。
クライアントが機能を発見する方法
クライアントがMCPサーバーに接続すると、利用可能なツールやリソースをリクエストします。つまり、どの機能が利用可能かを手動で設定する必要はありません。クライアントは次のことを行います:
- サーバーに接続してプロトコルハンドシェイクを完了する
- スキーマ付きの利用可能なツールの一覧をリクエストする
- 利用可能なリソースの一覧をリクエストする
- これらの機能をAIモデルが利用できるようにする
AIは、ユーザーのリクエストとツールの説明に基づいて、どのツールをいつ使用するかを判断できます。
その他のMCPサーバーのユースケース
MDCシンタックスヘルパーは一例に過ぎません。開発者は、組織全体の実際の課題を解決するためにMCPサーバーを構築しています。
社内開発向け:
- 企業のデザインシステムのドキュメントやコード生成
- 社内APIの利用ガイドと検証
- コーディング標準やアーキテクチャパターンの適用
- プライベートライブラリやツールのドキュメント
開発者向けワークフロー用:
- CI/CDパイプラインの統合とデプロイ自動化
- 課題管理およびプロジェクト管理(Jira、Linear、GitHub)
- エラー追跡およびデバッグツール(Sentry、Rollbar)
- コードレビューおよびリポジトリ管理
業務運営向け:
- 社内ナレッジベースやドキュメント検索
- 顧客データおよびCRMとの統合
- 分析ダッシュボードやデータウェアハウスへのクエリ
- 企業固有のワークフローやプロセスの自動化
利用可能なサーバーは、MCP Serversリポジトリで参照できます。
まとめ
MCPサーバーを構築することで、AIにドメイン特化の知識を付与できます。Cloudflare Workersにデプロイすれば、グローバルに分散した低遅延のサーバーを自動的にスケールさせることが可能です。
主なステップは以下の通りです:
- AIアシスタントが不足しているドメイン知識を特定する
- Agents SDK と MCP SDK を使って Cloudflare Worker プロジェクトをセットアップする
- Zod スキーマを使ったツールとリソースを備えた Agent クラスを作成する
- wrangler dev と MCP Inspector でローカルテストを行う
- Cloudflare にデプロイし、MCPクライアントが /mcp エンドポイント経由で接続できるよう設定する
詳細については、以下を参照してください:

Adam DeHaven
Senior Staff Software Engineer, Kong