Prometheus/Grafanaで観測するKong Gateway
Kong Gatewayは世界で最も利用されているAPI Gatewayであり、組織内外の多くのAPIトラフィックを扱う事ができます。Kong Gatewayを通ったトラフィックは客観的かつ横断的に観測出来るので、これらのメトリクスを効果的に活用できると可観測性の観点で強力な武器となります。
Kong Prometheus プラグインを利用すると、Kong Gateway本体だけでなく、通過するトラフィックに対する様々なメトリクスを収集する事が出来ます。本エントリではKong Prometheus プラグイン、Prometheus、そしてGrafanaを利用したトラフィックの観測について、実際に試せるサンプル環境の説明も交えてご説明します。
今回のサンプル環境はこちらに公開しております。
Kong Prometheus プラグイン
Kong Gatewayはプラグインアーキテクチャを採用しており、ルーティング以外の様々な機能性をゲートウェイに追加/構成する事が出来ます。プラグインは仕様並びにPlugin Development Kit (PDK) が公開されており誰でも開発することができますが、オープンソースを含め様々なプラグインが既に開発され利用する事ができます。Kongはプラグインの主要提供企業でもあります。
Kong Prometheus プラグインはKongがオープンソースで提供しているプラグインであり、どなたでも利用する事が出来ます。このプラグインは標準プラグインのひとつであり、Kongの提供バイナリの中に既に含まれています。特段インストール等の事前作業は不要で、設定を適用する事により利用できます。
メトリクスは<ADMIN_API_IP:PORT>/metricsというエンドポイントに公開されます。(検証用。本番環境ではStatus APIの利用を推奨します。)
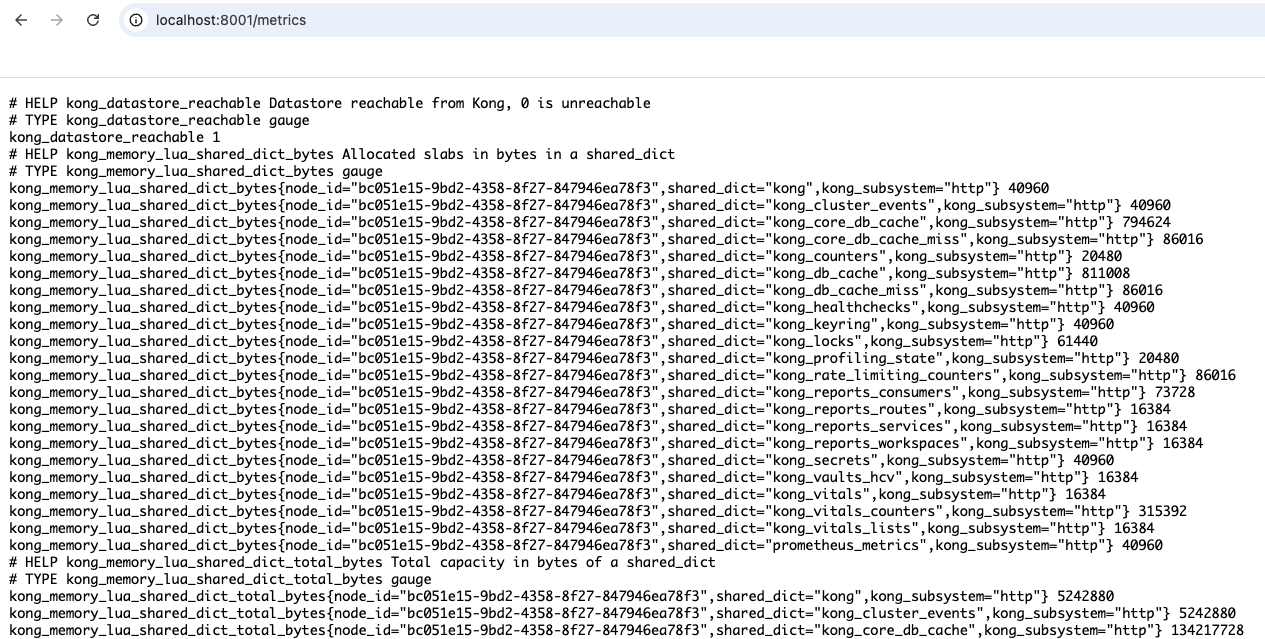
トラフィックに関するメトリクスは、メトリクスの物量に影響する為デフォルトではOffになっているので明示的に有効化する必要があります。具体的は per_consumer、 status_code_metrics、 latency_metrics、 bandwidth_metrics、upstream_health_metrics、ai_metricsの6つであり、プラグインのドキュメントに詳細が記載されています。デモ環境では起動後のKong GatewayのAdmin APIに対してREST POSTリクエストを実行する事により有効化しており、ここではper_consumer以外の全てを有効にしています。
メトリクス
メトリクス名は全てkong_で始まっており、種類に応じてkong_db_、kong_kong_latency_、kong_memory_lua、kong_request_latency_等命名されています。メトリクスにはCounter形式もGauge形式もありますが、トラフィック(Request、Latency、Upstream)に関するものはCounterのみになります。
以下がメトリクス一覧です:
| Name | Type | Remarks |
| kong_datastore_reachable | gauge | KongメタデータDB (Postgres) との接続状況。1が接続中で0が接続遮断中。 |
| kong_db_entities_total | gauge | 合計DBエンティティ数。 |
| kong_db_entity_count_errors | counter | エンティティカウント中のエラー発生有無。1がエラーありで0がエラーなし。 |
| kong_enterprise_license_errors | counter | ライセンス取得時の発生エラー件数。 |
| kong_bandwidth_bytes | counter | ゲートウェイ全体のトラフィックデータ量。direction = ingress/egressの2件出力。 |
| kong_memory_lua_shared_dict_bytes | gauge | 各コンポネントのシェアードメモリ利用量。コンポーネント数分出力され、コンポーネントめいがshared_dictに入る。 |
| kong_memory_lua_shared_dict_total_bytes | gauge | シェアードメモリの全量。 |
| kong_memory_workers_lua_vms_bytes | gauge | Worker VMのメモリ使用量。 |
| kong_nginx_connections_total | gauge | 各コンポーネントからNginxへの接続数。ステータス (state) 毎に出力。 |
| kong_nginx_metric_errors_total | counter | Prometheus Luaコンポーネントで発生したエラー数。 |
| kong_nginx_requests_total | gauge | リクエスト総数。 |
| kong_nginx_timers | gauge | Nginx timerのステータス毎 (pending/runnign) の総数。 |
| kong_node_info | gauge | Nodeの状態。基本的に常に1 (稼働中) |
| kong_http_requests_total | counter | HTTPステータスコード毎の総数。 (code) |
| kong_kong_latency_ms_bucket | counter | Kong自体の処理レイテンシ。Workspace / Service / Route 単位、複数のバケット毎に出力。 |
| kong_request_latency_ms_bucket | counter | リクエスト全体の処理レイテンシ。Workspace / Service / Route 単位、複数のバケット毎に出力。 |
| kong_upstream_latency_ms_bucket | counter | サービス。Workspace / Service / Route 単位、複数のバケット毎に出力。 |
| kong_upstream_target_health | gauge | Upstreamを指定した際のTarget毎の状態。Targetは物理ターゲット単位に出力。ステータスはhealthy / unhealthy / dns_error / healthchecks_off毎に出力され、該当するエントリに対して1が返される。 |
デモ環境においてはprometheus.ymlとして定義しています。特に特殊な設定はしていませんが、デフォルト値が大きいのでscrape_intervalとevaluation_intervalを15sに設定しています。(デフォルトは1m)
Grafanaダッシュボード
Kongでは公式にGrafana用ダッシュボードの定義を提供しています。このダッシュボードはKong Prometheusプラグインの中に含まれており、Grafanaであればそのまま使用する事が出来ます。
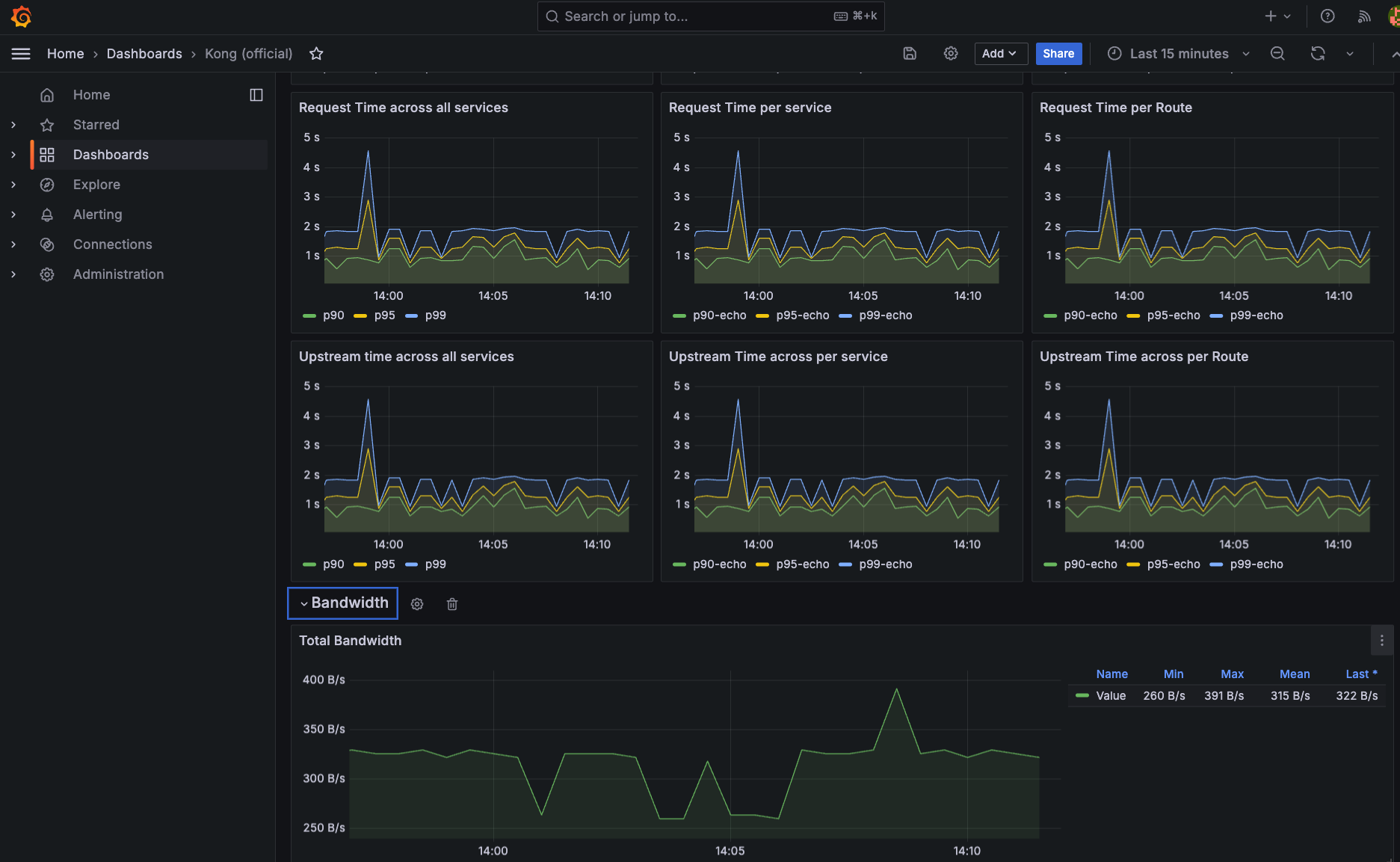
メトリクスはダッシュボードでは以下のように分類されています。
- Request rate – 全リクエスト、Service/Route毎のリクエスト、またService/Route毎HTTPステータスコード毎のに集計されており、それぞれのRPS (Request Per Second) を表示。
- Latency – リクエスト全体、Kong自体、接続先サービスそれぞれのレイテンシを、全リクエスト、Service毎、Route毎に集計した結果を表示。
- Bandwidth – スループットを、全体、Service毎、Route毎にingressとegressを分けて集計した結果を表示。
- Caching – 各コンポーネント毎、及びWorker (トラフィックを処理するコア) のシェアメモリ利用状況を表示。
- Upstream – Upstream/Targetを利用したサービスへのロードバランシングの状況 – それぞれのターゲット/物理IP単位におけるエラー発生状況をヒートマップとして表示。
- Nginx – Nginx観点から見たコネクション総数とステータス (
active/reading/waiting/writing) 毎の集計値をRPSとして表示。
このダッシュボードはKong Prometheusプラグインが収集する全てのメトリクスをカバーしている訳ではなく、またこのまま使う想定ともしておりません。あくまでベストプラクティスに基づいたスタート地点として捉え、運用に即してカスタマイズして利用する事をお勧めします。
また、KongのメトリクスはPrometheus形態での提供ではありますが、Prometheus/Grafanaでしか利用できない訳ではなく、比較的容易に他の観測基盤でも利用する事が出来ます。例えばNew Relicの場合、New Relic Infrastructure Flexを利用してメトリクスを収集する方法が紹介されています。
ハンズオン – サンプル環境
サンプル環境はDocker Composeを利用して全環境を一斉に立ち上げる構成となっており、docker compose upのコマンド実行で準備できます。

稼働するコンテナは6つ (kong、postgres、prometheus、grafana、httpbin x 2) 。初期設定用に別途2つのコンテナが起動しますが、これらは実行終了後にexitします。
httpbinはKenneth Reizさん作のテストサービスで、現在はPostmanのGitHubリポジトリにて管理されています。このサービスはテストで利用出来る様々なAPIを提供しており、中でも今回は/statusと呼ばれる指定したステータスコードを返すエンドポイントに対してアクセスします。また同サービスはhttps://httpbin.orgにてホスティングされているので、実際にAPIとして利用する事も出来ます。
Kong上のサンプル設定は以下の通りです:
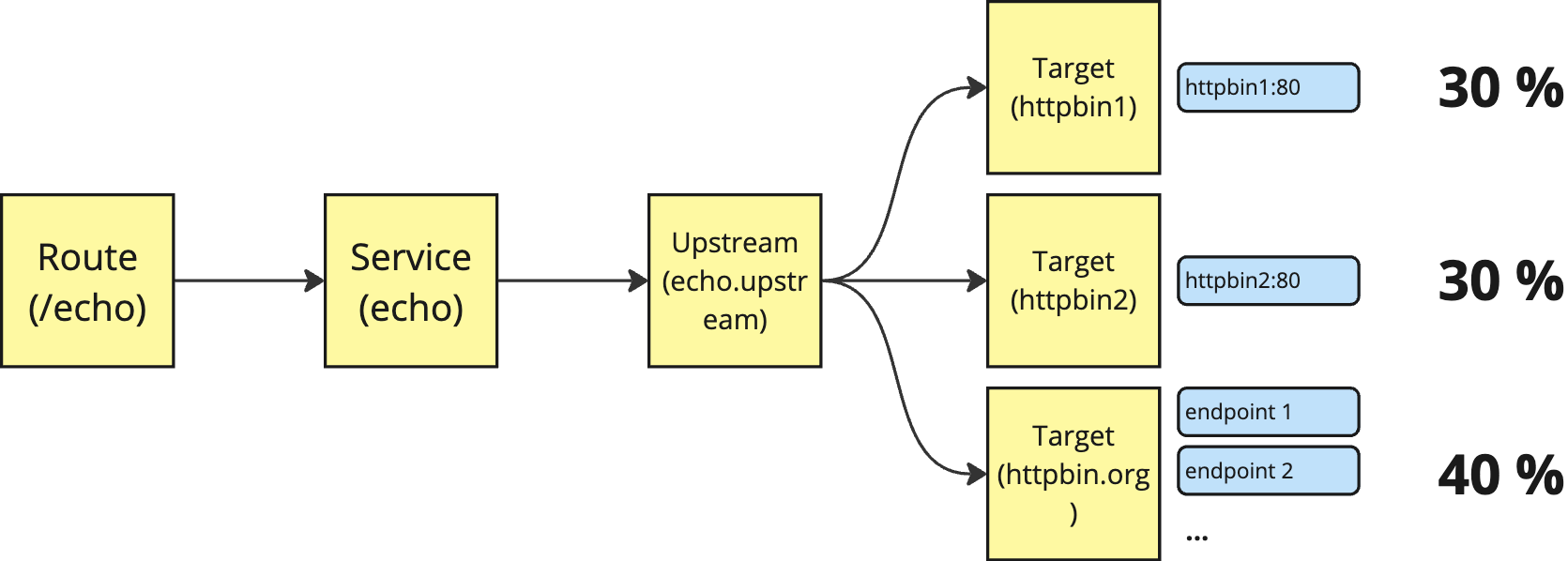
- Upstreamを
echo.upstreamという名前で登録。 - Targetは
httpbin1、httpbin2(いずれもDocker Composeによりコンテナとして稼働) と合わせてhttps://httpbin.orgも登録。 - Serviceからは
echo.upstreamをホストとして登録。 - Serviceには/echoという名前でRoute登録。
ゲートウェイでは1つのRouteのみ公開 (このサンプルでは http://localhost:8000/echo) されます。Upstreamは論理的なロードバランサとして機能しますが、Targetとして指定したエンドポイントに対してトラフィックのウェイトを指定する事が出来ます。ここでは外部のhttpbin.orgもターゲットに加える事により、クラスタの内外を跨いだ分散構成を再現しています。
上記サンプルのトラフィックを定義をすると以下のようになります:
_format_version: "3.0"
plugins:
- config:
bandwidth_metrics: true
latency_metrics: true
per_consumer: false
status_code_metrics: true
upstream_health_metrics: true
enabled: true
name: prometheus
services:
- enabled: true
host: status.upstream
name: status
path: /status
port: 80
protocol: http
routes:
- name: status
paths:
- /status
upstreams:
- healthchecks:
active:
http_path: /anything
name: status.upstream
slots: 10000
targets:
- target: httpbin.org:80
weight: 40
- target: httpbin1:80
weight: 30
- target: httpbin2:80
weight: 30このファイルはリポジトリにも追加しているので、decKを利用出来る場合は
deck gateway sync kong-target-lb.ymlと実行すると1コマンドでゲートウェイに反映出来ます。
ハンズオン – リクエストの送信と観測
Kong Gatewayへは同じRouteに対して継続してリクエストを送る事によりトラフィック全体の状態を観測できます。ブラウザやcurlを利用して継続してリクエストを送る事も出来ますが、今回はKong Insomniaを利用して継続的にリクエストを送信します。

http://localhost:8000/statusをGET HTTP Requestとして登録し、実行時にインターバルを指定して実行すると同じリクエストが継続的に実行されます。今回はUpstreamの/statusという、指定したステータスコードを返すエンドポイントを利用します。ステータスコードの指定はクエリに直接する事が出来ますが、今回はlocalhost:8000/status/200:0.7,429:0.2,500:0.1としています。この指定で:
- コード200: 正常終了 – 70%
- コード429: 流量制限エラー – 20%
- コード500: Upstreamエラー – 10%
とレスポンスが返ってくるようになり、エラー発生時のメトリクス状況を模擬的に再現しています。
Grafana上でこのトラフィックを観測してみます。
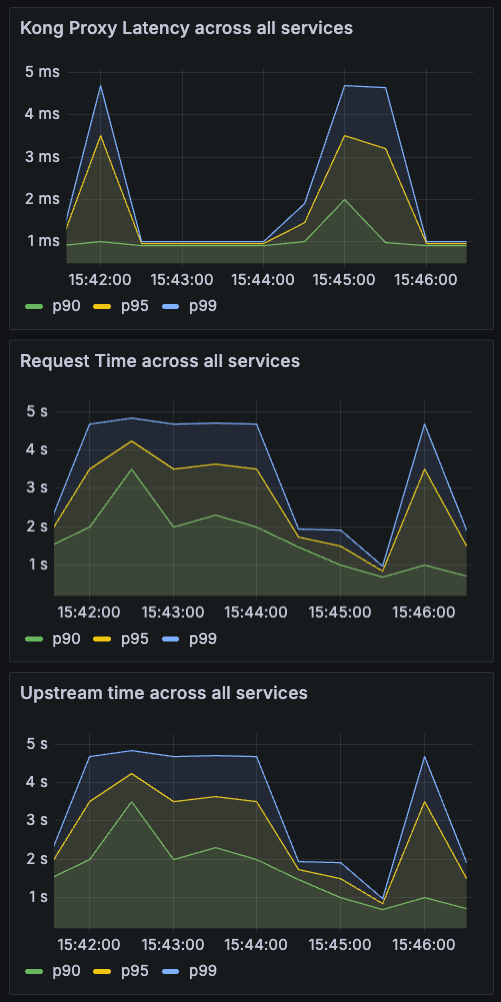
Kong Proxy (Kong Gatewayが処理にかけている時間) のメトリクスは接続対象に限らずほぼ均一のレイテンシを表しています。上昇する事もありますが、平均で1-2msに収まっています。
一方のRequest Time (リクエスト全体にかかる時間) は2s程度と非常に時間がかかっています。これはトラフィックの40%を占めるリクエストが、httpbin.org (パブリックのエンドポイント) に送られている為平均値が大幅に引き上げられている事が原因です。また、Upstream Time (Upstreamからの返信を待つ時間) がRequest Timeとほぼ同じであるところからも、処理のほとんどをUpstreamからの返答待ちに費やしている事が確認できます。
Target毎のレイテンシはメトリクスとして出力されていませんが、Targetの状態はダッシュボードのUpstreamに出力されています。

このパネルでは、接続先毎のヘルス状態がヒートマップとして表示されます。実際の運用ではTargetにてエラーが発生し、その頻度が高い場合にはより暖色に表示されます。ヒートマップは時系列に構成される為、観測期間におけるエラー発生傾向を捉える事が出来ます。
また、今回はhttpbin1、httpbin2、httpbin.orgと3つのTargetしか指定していませんが、エントリは7つ表示されています。これはTargetだけでなくTarget/Address毎に一意なメトリクスが出力される為で、httpbin.org自体が複数インスタンスに対してロードバランスしていることが理由です。
まとめ
Kong Gatewayは自身がPrometheus形態のメトリクスを出力する機能を有しており、Kong Prometheusプラグインによって簡単にその設定を制御する事が出来ます。KongではGrafana用のオフィシャルダッシュボードを提供していますが、Grafanaに限らず様々な観測基盤で他のコンポーネント同様に一元的に観測/監視をする事が出来ます。
ゲートウェイのレイヤーで横断的なトラフィックのメトリクスが取得出来ると、アプリ/インフラとは異なった側面でサービスの状態を捉える事が出来ます。これまでの可観測性にとって大きなプラスになると我々は考えています。

橋谷信一
Kong株式会社 シニア スタッフ ソリューション エンジニア